This is an old revision of the document!
Table of Contents
Configuration
In this section, you'll find advanced configuration tips
Priority to the nodes with the lower workload
This tip is useful for clusters of big nodes, like NUMA hosts with numerous cpus and a few nodes. When the cluster has a lot of free resources, users often wonder why their jobs are always sent to the first node while the others are completely free. With this simple trick, new jobs are sent preferably on the nodes that have the lowest 15 minutes workload.
Caution: Doing this will significantly reduce the chances for jobs that want to use entire nodes or big parts of them (they may wait for a longer time)! do so only if this is what you want!/
- First of all, create a new wload property:
oarproperty -a wload
- Then, create a script /usr/local/sbin/update_workload.sh that updates this property for each node of your cluster:
#!/bin/bash
set -e
HOSTS="zephir alize"
for host in $HOSTS
do
load=`ssh $host head -1 /proc/loadavg|awk '{print $3*100}'`
/usr/local/sbin/oarnodesetting -h $host -p wload=$load
done
- Add this script into your crontab, to be run every 5 minutes, for example inside /etc/cron.d/update_workload:
*/5 * * * * root /usr/local/sbin/update_workload.sh > /dev/null
- Then, add the wload field at the top of the SCHEDULER_RESOURCE_ORDER variable of your oar.conf file:
SCHEDULER_RESOURCE_ORDER="**wload ASC**,scheduler_priority ASC, suspended_jobs ASC, switch ASC, network_address DESC, resource_id ASC"
That's it!
Memory management in cpusets
Supposing you have a NUMA system (Non Uniform Access Memory), you may want to associate memory banks to sockets (cpus). This has 2 advantages:
- performance of jobs using only a part of a node
- a job having some cpus will go out of memory if it tries to access to memory of the others cpus (tipically, a one cpu job will obtain half of the memory on a 2-cpus host)
If you have a UMA system, you still may want to confine small jobs (ie jobs not using the entire node) to a subset of the memory and the trick is to use fake numa so that this tip will work for you.
All you have to do is to customize the job_resource_manager. It's a perl script, generally found into /etc/oar that you specify into the JOB_RESOURCE_MANAGER_FILE of the oar.conf file.
Examples (differences from the original script are set in bold):
Use fake-numa to add memory management into cpusets
With the linux kernel (depending on the version), it is possible to split the memory into a predefined number of chunks, exactly like if a chunk was corresponding to a memory bank. This way, it's then possible to associate some “virtual” memory banks to a cpuset. As OAR creates cpusets to isolate cpu workload from other jobs, it's also possible to isolate the memory usage. A job that tries to use more memory than the total amount of the virtual memory banks associated into its cpuset should swap or fail with a out of memory signal.
Fake-numa is activated at the boot process, by a kernel option, for example:
numa=fake=12
will create 12 slots of memory accessible from the cpusets filesystem:
bzeznik@gofree-8:~$ cat /dev/cpuset/mems 0-11
Each slot size is the total size of the node divided by 12.
Once activated into the kernel of your cluster's nodes, you should edit the OAR's job manager script to take this into account. This is a perl script, located into /etc/oar/job_resource_manager.pl on the OAR server. The easiest configuration is to create as many virtual memory banks as there are cores into your nodes. By this way, you have one virtual memory bank for one core and you can tell oar to associate the corresponding memory bank to a core:
# Copy the original job manager:
cp /etc/oar/job_resource_manager.pl /etc/oar/job_resource_manager_with_mem.pl
# Edit job_resource_manager_with_mem.pl, arround line 122, replace this line:
# 'cat /dev/cpuset/mems > /dev/cpuset/'.$Cpuset_path_job.'/mems &&'.
# by this line:
# '/bin/echo '.join(",",@Cpuset_cpus).' | cat > /dev/cpuset/'.$Cpuset_path_job.'/mems && '.
# (actually, it is the same line as for the "cpus", but into the "mems" file)
Once the new job manager created, you can activate it by changing the JOB_RESOURCE_MANAGER_FILE variable of your oar.conf file:
JOB_RESOURCE_MANAGER_FILE="/etc/oar/job_resource_manager_with_mem.pl"
Now, you can check if it's working by creating a new job, and checking into it's cpuset memory file. For example:
bzeznik@gofree:~$ oarsub -l /nodes=1/core=2 -I [ADMISSION RULE] Set default walltime to 7200. [ADMISSION RULE] Modify resource description with type constraints OAR_JOB_ID=307855 Interactive mode : waiting... Starting... Connect to OAR job 307855 via the node gofree-8 bzeznik@gofree-8:~$ cat /proc/self/cpuset /oar/bzeznik_307855 bzeznik@gofree-8:~$ cat /dev/cpuset/oar/bzeznik_307855/cpus 8-9 bzeznik@gofree-8:~$ cat /dev/cpuset/oar/bzeznik_307855/mems 8-9
Then you have to teach to your users that cores are associated to a certain amount of memory per core. In this example, it's 4GB/core. Then, if a user has a memory bounded job and needs 17GB of memory, he should ask for 5 cores on the same node, even for a sequential job. It's generally not to be considered as a waste in the HPC context because cpu cores are operating correctly only if memory i/o can operate correctly. It's also possible to create an admission rule that will convert a query like “-l /memory=17” into “-l /nodes=1/core=5”. Finally, it should also be possible to create more virtual memory banks (2 or 4… per core), but you then should have to create your resources as memory slots and manage a memory_slot property into the job manager for example.
Cpusets feature activation
If you want to use the cpusets feature, the JOB_RESOURCE_MANAGER_PROPERTY_DB_FIELD variable from your oar.conf file must be uncommented and set to the property that gives the cpuset ids of the resources (generally cpuset). This property must be configured properly for each resource. You can use the oar_resources_init command.
Start/stop of nodes using ssh keys
Nodes can set them automatically to the Alive status at boot time, and Absent status at shutdown. One efficient way to do this, is to use dedicated ssh keys. The advantages are:
- It is secure
- You need nothing special on the nodes but an ssh client
First of all, you need to add a ip property to the resources table and put the ip addresses of your nodes inside:
oarproperty -a ip -c oarnodesetting -p ip=192.168.0.1 --sql "network_address='node1'" oarnodesetting -p ip=192.168.0.2 --sql "network_address='node2'" ...
Then, you have to put 2 scripts into the /etc/oar directory:
- /etc/oar/oarnodesetting_ssh_alive.sh
#!/bin/sh # oarnodesetting_ssh: oarnodesetting SSH wrapper # $Id: oarnodesetting_ssh 949 2007-10-22 15:44:26Z capitn $ # This script is to be called from the node via SSH so that the server performs # the oarnodesetting command and changes the state of the calling node. # # NB: # 1- To get this script working, the oar ressource database table must have a # `ip' field containing the IP address for all the nodes # 2- A dedicated SSH key may be configured to restrict the ssh call capability # from the nodes to the server, by modifying the authorized_keys of oar on the # serveur as follows: # command="/usr/lib/oar/oarnodesetting_ssh" [dediacted pub key info]... # # Warning: if $IP does not exist in the database or every corresponding # resource states are 'Dead' then this script will return an exit code # of 12 not 0 (this is the default behaviour of "oarnodesetting"). IP=$(echo $SSH_CONNECTION | cut -d " " -f 1 ) OARNODESETTINGCMD=/usr/sbin/oarnodesetting [ -n "$IP" ] || exit 1 # This updates matching core/cpuset based on /proc/cpuinfo /etc/oar/update_cpuset_id.sh $IP # Set the node Alive exec $OARNODESETTINGCMD -s Alive --sql "ip = '$IP' AND state != 'Dead'" exit 1
- /etc/oar/oarnodesetting_ssh_absent.sh
#!/bin/sh # oarnodesetting_ssh: oarnodesetting SSH wrapper # $Id: oarnodesetting_ssh 949 2007-10-22 15:44:26Z capitn $ # This script is to be called from the node via SSH so that the server performs # the oarnodesetting command and changes the state of the calling node. # # NB: # 1- To get this script working, the oar ressource database table must have a # `ip' field containing the IP address for all the nodes # 2- A dedicated SSH key may be configured to restrict the ssh call capability # from the nodes to the server, by modifying the authorized_keys of oar on the # serveur as follows: # command="/usr/lib/oar/oarnodesetting_ssh" [dediacted pub key info]... # # Warning: if $IP does not exist in the database or every corresponding # resource states are 'Dead' then this script will return an exit code # of 12 not 0 (this is the default behaviour of "oarnodesetting"). IP=$(echo $SSH_CONNECTION | cut -d " " -f 1 ) OARNODESETTINGCMD=/usr/sbin/oarnodesetting [ -n "$IP" ] || exit 1 exec $OARNODESETTINGCMD -s Absent --sql "ip = '$IP' AND state != 'Dead'" exit 1
Then, create 2 ssh keys with no passphrase and put them inside the .ssh directory of the home of the oar user on every nodes:
sudo su - oar ssh-keygen -t rsa -f .ssh/oarnodesetting_alive.key ssh-keygen -t rsa -f .ssh/oarnodesetting_absent.key scp -P 6667 .ssh/oarnodesetting_a* node1:.ssh ...
Add the public keys, on your frontend, into the authorized_keys file of the oar user by prefixing them with the names of the scripts seen above:
environment="OAR_KEY=1",command="/etc/oar/oarnodesetting_ssh_alive.sh" ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAryzISWw4jbhphQfxWq2onrv8hZJlQo/aIjkDyh6wtriT9W289RB+SUNT7qnrDOcorgpwoCOdT6Y6ezlH2R2mLkbNyegV8q8wVTw0E96Rw7iBFXyyjsoq27E9J8ddlH6mE05G9vRaBDQiLJ76+lG20hnE1jhHiQX8DuFzG+qxmNiLGSIlYNCGNzP2RudQ6vdACzkOUw74dpwmJK0ko4YyHpxpbZ2/x66nJTINaIAPBJZ09FpUbWIRABOozr8u0GayiB06JOYnsbW0PqNUOGEvChYV8Kh3FJsM+geNh43I+uEo17p9DYhSGd1enPFOIv4VmPzZ3huT8TJH88FEz1F/zw ===== environment="OAR_KEY=1",command="/etc/oar/oarnodesetting_ssh_absent.sh" ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA3cM8AUC5F8Olb/umgjDztTOOWiRHj3WMy+js2dowfkO0s1yNkXa+L93UOC0L/BTSTbr8ZqGWV+yNvx36T8tFjWVnd+wkjwl616SxfEQQ1YXQWS8m55vPpCs3dT4ZvtSceB9G3XCoGje+fsOpNb05X9DhX+2bXwe69SwK3e8J7QkDIeRwcEiv6vrteHE04qaVBXTJGLgJToxcPKdKDNhPUUoA+f4ZO3OG0exrfhWNfrLpVqc69nOGiTI9/9N/Dmw/V5oAEvKED2H/Ek1EaptW7hCgZTHoyj9OXbpofSro768ecymRBa6/qfEC/LvSp9e2HYIjn5rcL0WqlKBajpblmQ==
Finaly, customize the oar-node init script (generally /etc/default/oar-node or /etc/sysconfig/oar-node) with the following script:
## Auto update node status at boot time # # OARREMOTE: machine where we remotely run oarnodesetting (e.g. the main oar+kadeploy frontend) OARREMOTE="172.23.0.3" # retry settings MODSLEEP=8 MINSLEEP=2 MAXRETRY=30 start_oar_node() { test -n "$OARREMOTE" || exit 0 echo " * Set the ressources of this node to Alive" local retry=0 local sleep=0 until ssh -t -oStrictHostKeyChecking=no -oPasswordAuthentication=no -i /var/lib/oar/.ssh/oarnodesetting_alive.key oar@$OARREMOTE -p 6667 do if [$((retry+=sleep)) -gt $MAXRETRY ]; then echo "Failed." return 1 fi ((sleep = $RANDOM % $MODSLEEP + $MINSLEEP)) echo "Retrying in $sleep seconds..." sleep $sleep done return 0 } stop_oar_node() { test -n "$OARREMOTE" || exit 0 echo " * Set the ressources of this node to Absent" local retry=0 local sleep=0 until ssh -t -oStrictHostKeyChecking=no -oPasswordAuthentication=no -i /var/lib/oar/.ssh/oarnodesetting_absent.key oar@$OARREMOTE -p 6667 do if [$((retry+=sleep)) -gt $MAXRETRY ]; then echo "Failed." return 1 fi ((sleep = $RANDOM % $MODSLEEP + $MINSLEEP)) echo "Retrying in $sleep seconds..." sleep $sleep done return 0 }
You can test by issuing the following from a node:
node1:~ # /etc/init.d/oar-node stop Stopping OAR dedicated SSH server: * Set the ressources of this node to Absent 33 --> Absent 34 --> Absent 35 --> Absent 36 --> Absent 37 --> Absent 38 --> Absent 39 --> Absent 40 --> Absent Check jobs to delete on resource 33 : Check done Check jobs to delete on resource 34 : Check done Check jobs to delete on resource 35 : Check done Check jobs to delete on resource 36 : Check done Check jobs to delete on resource 37 : Check done Check jobs to delete on resource 38 : Check done Check jobs to delete on resource 39 : Check done Check jobs to delete on resource 40 : Check done Connection to 172.23.0.3 closed. node1:~ # /etc/init.d/oar-node start Starting OAR dedicated SSH server: * Set the ressources of this node to Alive 33 --> Alive 34 --> Alive 35 --> Alive 36 --> Alive 37 --> Alive 38 --> Alive 39 --> Alive 40 --> Alive Done Connection to 172.23.0.3 closed.
Multicluster
You can manage several different clusters with a unique OAR server. You may also choose to have one or several submission hosts. Simply install the oar-server package on the server and the oar-user package on all the submission hosts.
You can tag the resources to keep track of which resource belongs to which cluster. Simply create a new property (for example: “cluster”) and set it for each resource. Example:
oarproperties -c -a cluster for i in `seq 1 32`; do oarnodesetting -r $i -p cluster="clusterA"; done for i in `seq 33 64`; do oarnodesetting -r $i -p cluster="clusterB"; done
Users can choose on which cluster to submit by asking for a specific cluster value:
oarsub -I -l /nodes=2 -p "cluster='clusterA'"
If you have several submission hosts, you can make an admission rule to automatically set the value of the cluster property. For example, the following submission rule should do the trick:
# Title : Cluster property management # Description : Set the cluster property to the hostname of the submission host use Sys::Hostname; my @h = split('\\.',hostname()); # If you want to set up a queue per cluster, you can uncomment the following: #if ($queue_name eq "default") { # $queue_name=$h[0]; #} if ($jobproperties ne ""){ $jobproperties = "($jobproperties) AND cluster = '".$h[0]."'"; } else{ $jobproperties = "cluster = '".$h[0]."'"; }
Finally, you may also want to set up a queue per cluster, just because it's nicer in the oarstat output:
oarnotify --add_queue "clusterA,5,oar_sched_gantt_with_timesharing" oarnotify --add_queue "clusterB,5,oar_sched_gantt_with_timesharing"
How to prevent a node to be suspected when it was rebooted during the job or when using several network_address properties on the same physical computer
In /etc/oar/job_resource_manager.pl simply uncomment the #exit(0) line.
Activating the oar_phoenix script to automatically reboot suspected nodes
Note: this tips depends on the start/stop of nodes using ssh keys tips, for the node to be automatically set up to the alive state at boot time.}} OAR server now comes with a perl script, located into /etc/oar/oar_phoenix.pl that searches for fully suspected nodes and may send customized commands aimed at repairing them. It has a 2 level mechanism: First, it sends a 'soft' command. And after a timeout, if the node is still suspected, it sends a 'hard' command. Here is how to install the script:
- Edit the customization part of the phoenix script to set up your soft and hard commands. The '{nodename}' macro is set to pass the node name to the commands; here is an example:
cluster:~# vi **/etc/oar/oar_phoenix.pl** # Command sent to reboot a node (first attempt) my $PHOENIX_SOFT_REBOOTCMD="ssh -p 6667 {nodename} oardodo reboot"; # Timeout for a soft rebooted node to be considered hard rebootable my $PHOENIX_SOFT_TIMEOUT=300; # Command sent to reboot a node (second attempt) #my $PHOENIX_HARD_REBOOTCMD="oardodo ipmitool -U USERID -P PASSW0RD -H {nodename}-mgt power off;sleep 2;oardodo ipmitool -U USERID -P PASSW0RD -H {NODENAME}-mgt power on"; my $PHOENIX_HARD_REBOOTCMD="oardodo /etc/oar/reboot_node_hard.sh {nodename}";
- Create a cron job that runs perdiodically phoenix:
cluster:~# vi **/etc/cron.d/oar-phoenix** */10 * * * * root /usr/sbin/oar_phoenix
Use cases
OpenMPI + affinity
We saw that the Linux kernel seems to be incapable of using correctly all the CPUs from the cpusets.
Indeed, reserving 2 out of 8 cores on a node and running a code that uses 2 process, these 2 process where not well assigned to each cpu. We had to give the CPU MAP to OpenMPI to do cpu_affinity:
i=0 ; oarprint core -P host,cpuset -F "% slot=%" | while read line ; do echo "rank $i=$line"; ((i++)); done > affinity.txt [user@node12 tmp]$ mpirun -np 8 --mca btl openib,self -v -display-allocation -display-map --machinefile $OAR_NODEFILE -rf affinity.txt /home/user/espresso-4.0.4/PW/pw.x < BeO_100.inp
NUMA topology optimization
In this use case, we've got a numa host (an Altix 450) having a “squared” topology: nodes are interconnected by routers like in this view:
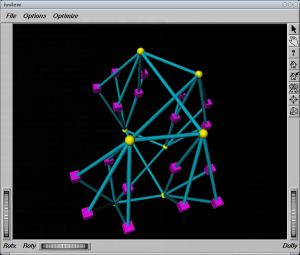 In yellow, “routers”, in magenta, “nodes” (2 dual-core processors per node)
In yellow, “routers”, in magenta, “nodes” (2 dual-core processors per node)
Routers interconnect IRUS (chassis) on which the nodes are plugged (4 or 5 nodes per IRU).
What we want is that for jobs that can enter into 2 IRUS or less, minimize the distance between the resources (ie use IRUS that have only one router interconnexion between them). The topology may be siplified as follows:
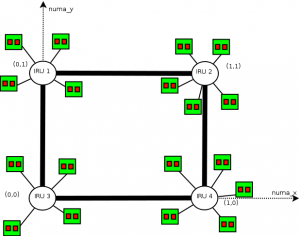
The idea is to use moldable jobs and an admission rule that converts automatically the user requests to a moldable job. This job uses 2 resource properties: numa_x and numa_y that may be analogue to the square coordinates. What we want in fact, is the job that ends the soonest between a job running on an X or on a Y coordinate (we only want vertical or horizontal placed jobs).
The numa_x and numa_y properties are set up this way (pnode is a property corresponding to physical nodes):
{|border=“1” !pnode !iru !numa_x !numa_y
For example, the following requested ressources:
-l /core=16
will result into:
-l /numa_x=1/pnode=4/cpu=2/core=2 -l /numa_y=1/pnode=4/cpu=2/core=2
Here is the admission rule making that optimization:
# Title : Numa optimization # Description : Creates a moldable job to take into account the "squared" topology of an Altix 450 my $n_core_per_cpus=2; my $n_cpu_per_pnode=2; if (grep(/^itanium$/, @{$type_list}) && (grep(/^manual$/, @{$type_list}) == "") && $#$ref_resource_list == 0){ print "[ADMINSSION RULE] Optimizing for numa architecture (use \\"-t manual\\" to disable)"; my $resources_def=$ref_resource_list->[0]; my $core=0; my $cpu=0; my $pnode=0; foreach my $r (@{$resources_def->[0]}) { foreach my $resource (@{$r->{resources}}) { if ($resource->{resource} eq "core") {$core=$resource->{value};} if ($resource->{resource} eq "cpu") {$cpu=$resource->{value};} if ($resource->{resource} eq "pnode") {$pnode=$resource->{value};} } } # Now, calculate the number of total cores my $n_cores=0; if ($pnode == 0 && $cpu != 0 && $core == 0) { $n_cores = $cpu*$n_core_per_cpus; } elsif ($pnode != 0 && $cpu == 0 && $core == 0) { $n_cores = $pnode*$n_cpu_per_pnode*$n_core_per_cpus; } elsif ($pnode != 0 && $cpu == 0 && $core != 0) { $n_cores = $pnode*$core; } elsif ($pnode == 0 && $cpu != 0 && $core != 0) { $n_cores = $cpu*$core; } elsif ($pnode == 0 && $cpu == 0 && $core != 0) { $n_cores = $core; } else { $n_cores = $pnode*$cpu*$core; } print "[ADMINSSION RULE] You requested $n_cores cores\"; if ($n_cores > 32) { print "[ADMISSION RULE] Big job (>32 cores), no optimization is possible"; }else{ print "[ADMISSION RULE] Optimization produces: /numa_x=1/$pnode/$cpu/$core /numa_y=1/$pnode/$cpu/$core"; my @newarray=eval(Dumper(@{$ref_resource_list}->[0])); push (@{$ref_resource_list},@newarray); unshift(@{%{@{@{@{$ref_resource_list}->[0]}->[0]}->[0]}->{resources}},{'resource' => 'numa_x','value' => '1'}); unshift(@{%{@{@{@{$ref_resource_list}->[1]}->[0]}->[0]}->{resources}},{'resource' => 'numa_y','value' => '1'}); } }
Troubles and solutions
Can't do setegid!
Some distributions have perl_suid installed, but not set up correctly. The solution is something like that:
bzeznik@healthphy:~> which sperl5.8.8 /usr/bin/sperl5.8.8 bzeznik@healthphy:~> sudo chmod u+s /usr/bin/sperl5.8.8
Users tips
oarsh completion
Tip based on an idea from Jerome Reybert
In order to complete nodes names in a oarsh command, add these lines in your .bashrc
function _oarsh_complete_() { if [ -n "$OAR_NODEFILE" -a "$COMP_CWORD" -eq 1 ]; then local word=${comp_words[comp_cword]} local list=$(cat $OAR_NODEFILE | uniq | tr '\n' ' ') COMPREPLY=($(compgen -W "$list" -- "${word}")) fi } complete -o default -F _oarsh_complete_ oarsh
Then try oarsh <TAB>
OAR aware shell prompt for Interactive jobs
If you want to have a bash prompt with your job id and the remaining walltime then you can add in your ~/.bashrc:
if [ "$PS1" ]; then __oar_ps1_remaining_time(){ if [ -n "$OAR_JOB_WALLTIME_SECONDS" -a -n "$OAR_NODE_FILE" -a -r "$OAR_NODE_FILE" ]; then DATE_NOW=$(date +%s) DATE_JOB_START=$(stat -c %Y $OAR_NODE_FILE) DATE_TMP=$OAR_JOB_WALLTIME_SECONDS ((DATE_TMP = (DATE_TMP - DATE_NOW + DATE_JOB_START) / 60)) echo -n "$DATE_TMP" fi } PS1='[\u@\h|\W]$([ -n "$OAR_NODE_FILE" ] && echo -n "(\[\e[1;32m\]$OAR_JOB_ID\[\e[0m\]-->\[\e[1;34m\]$(__oar_ps1_remaining_time)mn\[\e[0m\])")\$ ' if [ -n "$OAR_NODE_FILE" ]; then echo "[OAR] OAR_JOB_ID=$OAR_JOB_ID" echo "[OAR] Your nodes are:" sort $OAR_NODE_FILE | uniq -c | awk '{printf(" %s*%d", $2, $1)}END{printf("\n")}' | sed -e 's/,$//' fi fi
Then the prompt inside an Interactive job will be like:
[capitn@node006~](3101-->29mn)$
Many small jobs grouping
Many small jobs of a few seconds may be painful for the OAR system. OAR may spend more time scheduling, allocating and launching than the actual computation time for each job.
Gabriel Moreau developed a script that may be useful when you have a large set of small jobs. It groups you jobs into a unique bigger OAR job:
You can download it from this page:
For a more generic approach you can use Cigri, a grid middleware running onto OAR cluster(s) that is able to automatically group parametric jobs. Cigri is currently in a re-writing process and a new public release is planned for the end of 2012.
Please contact Bruno.Bzeznik@imag.fr for more informations.
